
What are OWASP’s Top 10 API vulnerabilities?

APIs are pervasive, they’re everywhere. Organizations use APIs more and more as part of their product strategy, to automate internal processes, and to drive integrations between their own services. In 2017, McKinsey estimated that APIs will fuel $1 trillion in profits by 2025 (a modern estimate would likely be higher).
But with the growing use of APIs, there’s also an increased security risk. APIs represent gateways to our systems, and if they’re not properly secured, we’re almost guaranteed to get screwed. Poor API security is estimated to cost organizations $75 billion per year and is set to become uninsurable.
Despite the risk, there’s no doubt that APIs are a fundamental competitive advantage for modern organizations, so we want to do everything we can to continue using them. What should you do if you want to keep using APIs and do it securely? A good way to get started with API security is OWASP’s Top 10 list of API security vulnerabilities. It describes the most common API vulnerabilities and how to protect yourself from them. Of course there are a lot more things to consider when it comes to API security, but this is a good starting point.
The top 10 vulnerabilities are:
Broken Object Level Authorization
Broken User Authentication
Excessive Data Exposure
Lack of Resources & Rate Limiting
Broken Function Level Authorization
Mass Assignment
Security Misconfiguration
Injection
Improper Assets Management
Insufficient Login & Monitoring
Let’s discuss each vulnerability in detail.
Broken Object Level Authorization
Broken Object Level Authorization happens when we fail to enforce user-based access to every resource. Typically, APIs have restricted access to information. For example, in a blogging application, only the author of a post has the right to edit it, and the API must enforce this access restriction.
Attackers approach this vulnerability by leveraging resource endpoints with IDs. As you can see in the image below, if our API exposes an endpoint that represents a blog post with the format /posts/{blogId}, an attacker will play around with different IDs to try and get access to information they shouldn’t be allowed to access. They may also try to perform operations on the resource using POST/PUT/DELETE endpoints. In the worst cases, an attacker may be able to take over another user’s account if they can manipulate the users’ endpoints.

To protect yourself against this vulnerability, you must check across all your endpoints whether the user sending the request has access to the requested information or operations.
Broken User Authentication
This vulnerability happens when user authentication is incorrectly implemented. Authentication is the process of verifying a user’s identity, and through this mechanism we often issue access tokens too. When it comes to APIs, we often use OpenID Connect (OIDC) to prove a user’s identity, and Open Authorization (OAuth) to issue access tokens. Unfortunately, implementing these flows correctly isn’t always easy. And if the authentication process is incorrectly implemented, we open the door for attackers to get hold of access tokens from other users.

Broken user authentication comes in many forms and, in my experience, it’s widely spread. The most common case is when the OIDC and OAuth protocols aren’t correctly implemented. The easiest way to get around this is using an OIDC and OAuth provider. We must also ensure we’re using the correct OAuth flows for each scenario and that we’re using the right type of tokens. On the API server side, we must apply robust validation on the tokens.
Excessive Data Exposure
Excessive data exposure happens when we expose more data than is needed through the API. For example, in collection endpoints (i.e. endpoints that return lists of objects), it’s common to return more items than the client needs, and let the client filter out those they don’t need or those that the user shouldn’t be allowed to access. This is very dangerous, since an attacker calling the API directly or inspecting the traffic will see the whole payload, and they could use this information to launch surface attacks on the API. If the API also suffers from “broken object level authorization”, the attacker will then get access to resources they shouldn’t be able to access.
This vulnerability also happens when we return objects with more information than the client needs, specially IDs. For example, as you can see in the image below, in a ride sharing application, we may have an endpoint that returns the details of a ride. If the payload includes unnecessary information, like the car’s ID and the car owner’s ID, an attacker may use the information to try and get hold of those resources.
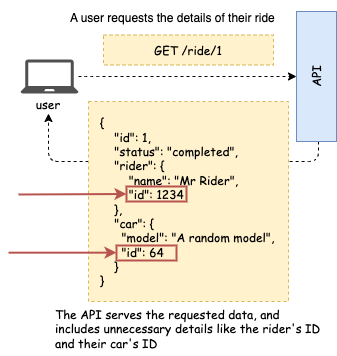
Healthcare APIs are particularly vulnerable to this type of attack, since the shape of the payload often depends on the type of user who’s requesting the information, and we must be extra careful in the backend to ensure that the payload doesn’t include a single bit of unnecessary information.
Lack of Resources and & Rate Limiting
This vulnerability happens when we don’t restrict how often a user can access the API. Without rate limiting, an attacker can launch a Denial of Service Attack (DDoS) and bring our servers down (or make us bankrupt if our cloud computing services are set to scale without limit 😅). They can also exploit this vulnerability for brute force attacks, to try and break our authorization system by attempting to log in multiple times, or trying to access a resource with different tokens.
Attackers can launch a DDoS attack with strategies such as sending thousands of requests per second, sending very large payloads, triggering expensive processes in the server, or by requesting large amounts of data from the API.

To protect ourselves against these attacks, we must limit the number of API calls a user can make in a given time period. For expensive endpoints, that is endpoints that engage in CPU-intensive operations or load a lot of data from the database, we may include stricter rate limits. We must also constrain the size of the payloads users can send to the server, and the amount of data we can serve in a response. We may also want to limit the maximum amount of memory that a threat or process can consume while processing a request.
Broken Function Level Authorization
This vulnerability happens when access to API resources and operations is based on the user group or function and we fail to adequately check which group or function a user belongs to. Most APIs have categories and hierarchies of users with different access privileges. Sometimes, different user groups use the same endpoints, and the code determines how to handle the request depending on the user; and sometimes, the API exposes different endpoints for different groups of users (e.g. an /admins path for administrative users); and yet sometimes, the type of user is indicated in a custom header. All approaches can lead to vulnerabilities depending on the implementation.
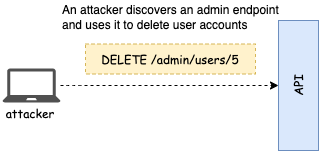
When all users have access to different information through the same endpoints, the logic determining the access privilege of the user is often complex and results in unexpected behaviors, which can be leveraged by an attacker trying to access resources or operations they shouldn’t be able to have access to.
When different groups of users have access through different endpoints, an attacker may perform a surface attack on the API to try and discover those endpoints. If access validation in those endpoints doesn’t adequately check the type of user before serving the request, the API will leak data to the attacker. Same for the request header approach.
Mass assignment
Mass assignment happens when we accidentally allow a user to change data they shouldn’t be able to modify. This vulnerability comes in different forms. A typical example is when a user updates a resource. Normally, a resource has a set of writable and a set of read-only (or server-side) properties. In some cases, the API implementation may not check carefully the data sent by the user to update a resource and bind it to the target resource. An attacker can leverage this vulnerability to elevate their user privileges, increase their credit balance, alter the state of their orders, or to corrupt data.

To protect yourself against this vulnerability, always validate the input sent by the user. Input payloads shouldn’t allow server-side properties and therefore should be rejected even before we begin to process them.
A variation of this vulnerability happens when we have specific endpoints to update sensitive information, like user group, ratings, credit, and so on. For example, an API may have an endpoint POST /user/{userId}/rating that can be used to update the user rating, and a malicious actor can leverage this exposure to update the rating. If we have such endpoints, it’s best to restrict their access to a private network and have a very robust access validation layer in the code.
Security misconfiguration
Security misconfiguration refers to application and infrastructure misconfiguration that can compromise API security. For example, permissive CORS policies, missing TLS, leaking stack trace in error messages, misconfigured HTTP headers, exposing unnecessary HTTP methods, and so on. It also includes unprotected S3 buckets, running services like databases insecurely (e.g. in default port, with authentication disabled, in public networks, etc.). Depending on the security of the problem, a malicious user can leverage security misconfiguration to obtain information about the system and even gain access to it.
Injection
Injection happens when an attacker injects malicious code through the API, such as SQL/noSQL injection queries that get executed in the database, or command injection statements that get executed in the server. An attacker can leverage any input field in the API to launch an injection attack, including URL query and path parameters, request payloads, header values, field values in a JWT, and so on.

The best line of defense against injection is to parametrize your queries. All too often, I see code with query templates that simply interpolates parameters, easily leading to injection attacks. If you use custom queries, remember to parametrize user input!
The second thing you want to do to protect yourself against this type of attack is to strictly validate user input in the API layer. Enforce whatever type, format, or value constraints your parameters have. If a query parameter is an integer, validate it accordingly. If it’s an enumeration, don’t allow any other random values. Input validation at the API layer won’t filter out all sorts of injection attacks (e.g. plain string fields are still a vector), but it’ll go a long way to ensuring safe input.
Improper Asset Management
Improper asset management refers to the improper exposure of API endpoints, versions, or hosts. Sometimes, APIs have debug or testing endpoints that are not meant to be publicly exposed. If those endpoints make their way into a public network, a malicious actor can use them as an attack vector.
When releasing a new version of the API, we must carefully sunset older versions and ensure they’re not publicly exposed once they’re deprecated. This is especially important when the new version includes security improvements.

Improper asset management is more likely to happen when our organization lacks proper API management and when we’re not API-first. A lot of organizations suffer from API sprawl and from legacy APIs that are not properly documented. Lack of documentation is dangerous, since it makes API management more difficult, and often organizations become unaware of how many assets (i.e. endpoints, versions, hosts, and so on) they’re exposing, leaving them vulnerable to exploitation attacks.
Insufficient Logging & Monitoring
Insufficient logging and monitoring means we lack API visibility. API visibility isn’t just having logs, it’s having active monitoring of those logs. API monitoring helps to understand the health of our APIs and how they’re being used. It helps to trace bugs across distributed transactions. It helps to detect performance issues and integration problems early on. When properly done, it also helps to detect excessive sensitive data exposure.
In my experience, insufficient logging and monitoring is the most common API vulnerability, which explains why it takes most organizations over 200 days to detect an API breach. Most organizations can’t even answer what their most commonly used endpoints are, or what the typical user journey through their APIs is. Distributed transactions are often difficult to debug, because we have no way of tracing a request through various services.

The first step to fixing this problem is to automate the setting up of logging and monitoring tools. Treat logging and monitoring as part of your infrastructure and make sure it’s deployed in every environment. Centralize log collection and monitor them actively. Look for suspicious patterns in the logs and build dashboards with usage analytics. Document latencies, errors and their types, user journeys, and any other kind of information that may be useful for your API management strategy.
Additional resources
To learn more about OWASP’s Top 10 API Vulnerabilities, check out the official website. The list is currently under review for the 2023 edition, and if you have experience with APIs and security, you can contribute your ideas!
APISecurity.io is a great resource about API security and API breaches, and they have a great section dedicated to OWASP’s Top 10 API Vulnerabilities. I highly recommend you check it out!
If you want to learn more about API security, join me in my upcoming free webinar “API Security Fundamentals” on March 15. If you can’t make it that day, don’t worry, I’ll run more editions later this year and I’ll announce them here in the newsletter.
If you liked this post, you’ll like my book Microservice APIs. Use the code slperalta to obtain a 40% Manning’s website. You can also get the book on Amazon.com.
At microapis.io I’m constantly helping organizations design and deliver their microservices and APIs reliably and securely. If you work with these technologies, don't hesitate to get in touch!